2024年12月26日,DeepSeek-V3横空出世,以其卓越性能备受瞩目。该模型发布即支持昇腾,用户可在昇腾硬件和MindIE推理引擎上实现高效推理,但在实际操作中,部署流程与常见问题困扰着不少开发者。本文将为你详细阐述昇腾 DeepSeek 模型部署的优秀实践,同时解答常见问题。
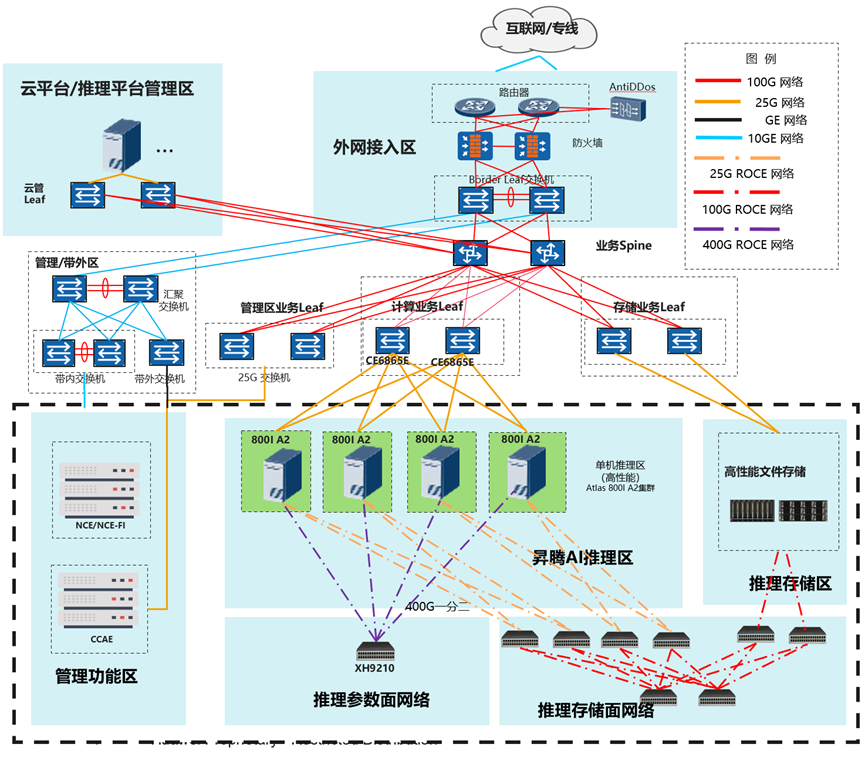
1 DeepSeek在昇腾上的模型部署优秀实践
1.1 硬件要求及组网
推荐参考配置如下,部署DeepSeek-V3/R1量化模型需要多节点Atlas 800I A2(至少2*8*64G)服务器。本方案以DeepSeek-R1为主进行介绍,DeepSeek-V3与R1的模型结构和参数量一致,部署方式与R1相同。
1.2 运行环境准备
推荐使用镜像部署
1.2.1 镜像部署
昇腾官方在Ascend hub提供环境示例镜像,含推理部署配套软件以及模型运行脚本,用户可参考构建运行环境镜像进行部署。
镜像部署及启动参照ModelZoo指南中“加载镜像”章节,该指南中还包含“容器启动”等指引
镜像申请/下载(含于上述指南):
https://www.hiascend.com/developer/ascendhub/detail/af85b724a7e5469ebd7ea13c3439d48f
1.2.2 裸机部署
根据昇腾社区发布的MindIE安装指南安装软件包和运行依赖软件
安装指南:
根据指南安装全部软件包和环境
https://www.hiascend.com/document/detail/zh/mindie/100/envdeployment/instg/mindie_instg_0001.html
模型获取:
1.3 权重文件准备
BF16权重下载:
1、HuggingFace:https://huggingface.co/unsloth/DeepSeek-V3-bf16/
2、ModelScope:https://modelscope.cn/models/unsloth/DeepSeek-V3-bf16/
3、Modelers:https://modelers.cn/models/State_Cloud/DeepSeek-V3-BF16
INT8量化后权重下载:
State_Cloud/DeepSeek-R1-W8A8 | 魔乐社区
如已下载BF16模型,也可采用以下步骤进行模型量化,权重BF16->INT8转换预计7~8小时。
Step1:安装ModelSlim
git clone https://gitee.com/ascend/msit.git
cd msit/msmodelslim
bash install.sh
Step2: 运行量化命令
cd msit/msmodelslim/example/DeepSeek/
python3 quant_deepseek_w8a8.py \
--model_path {浮点权重路径} \
--save_path {W8A8量化权重路径}
更多详细量化教程请参考 DeepSeek 量化文档( https://gitee.com/ascend/msit/tree/br_noncom_MindStudio_8.0.0_POC_20251231/msmodelslim/example/DeepSeek)
Msmodelslim 代码仓: https://gitee.com/ascend/msit/tree/br_noncom_MindStudio_8.0.0_POC_20251231/msmodelslim
1.4 运行前检查
软件版本配套检查,含:HDK、CANN、PTA、MindIE、MindStudio
1.4.1 检查组网链接状态
a) 检查物理链接
for i in {0..7}; do hccn_tool -i $i -lldp -g | grep Ifname; done
b) 检查链接情况
for i in {0..7}; do hccn_tool -i $i -link -g ; done
c) 检查网络健康情况
for i in {0..7}; do hccn_tool -i $i -net_health -g ; done
d) 查看侦测ip的配置是否正确
for i in {0..7}; do hccn_tool -i $i -netdetect -g ; done
e) 查看网关是否配置正确
for i in {0..7}; do hccn_tool -i $i -gateway -g ; done
f) 检查NPU底层tls校验行为一致性,建议全0
for i in {0..7}; do hccn_tool -i $i -tls -g ; done | grep switch
g) # NPU底层tls校验行为置0操作
for i in {0..7};do hccn_tool -i $i -tls -s enable 0;done
1.4.2 根据组网设置准备rank_table_file.json
使用多节点推理时,需要将包含设备ip,服务器ip等信息的json文件地址传递给底层通信算子。参考如下格式,配置rank_table_file.json:

1.5 模型部署与配置
独立模型:
服务化部署:
1、运行指南
2、服务启动
1、接口指引
1.6 模型运行
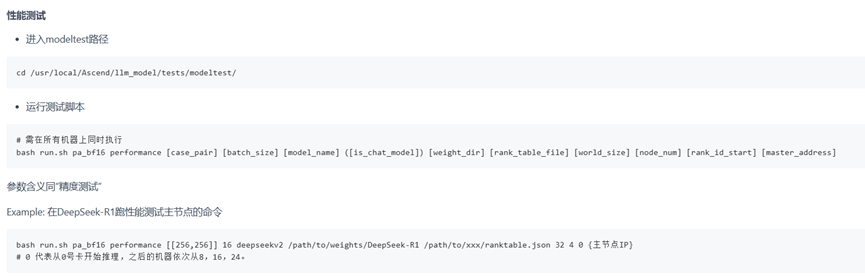
1.6.1 纯模型测试
模型脚本已预制在镜像中,参照以下链接即可拉起精度测试及模型测试
1.6.2 服务化测试
1、运行指南
2、服务启动
3、常用接口指引
2 常见问题及解决方案
2.1 通信错误:Hccl execute failed
问题现象:
日志显示卡(IP地址10.0.3.9)与卡(IP地址10.0.3.17)之间connection fail
查看日志发现出现hccl通信失败相关日志内容:


解决方案:
(1)问题定位前需要先开启日志生成环境变量:
算子库&加速库&模型库日志保存路径:/root/atb/log
CANN日志保存路径:/root/ascend/log/debug/plog
(2)通过hccn_tool 工具进行连通性检测,发现出现链路down,修复链路down的问题后,通信失败问题解决。
2.2 通信错误:HCCL通信超时
可配置以下环境变量,增大超时等待时间。
2.3 显存不足:NPU out of memory
问题现象:
在服务化拉起过程中,出现NPU out of memory报错。
解决方案:
适当调高NPU_MEMORY_FRACTION环境变量(默认值为0.8),适当调低mindie-service服务化配置文件config.json中maxSeqLen、maxInputTokenLen、maxPrefillBatchSize、maxPrefillTokens、maxBatchSize等参数
2.4 推理卡顿:模型加载时间长,可能达到2H及以上
问题现象:模型部署过程中,推理前的模型加载时间过长,部分极端情况需要等待>2H
可能原因:
1)用户场景内存不足导致swap介入;
2)首次加载权重,权重存储硬件的传输速率慢,传统的HDD或低速SSD或网络存储方式存在I/O瓶颈;
3)框架权重加载使用单线程加载;
解决方案:
1)更换NVMe SSD高速存储硬件;
2) 使用内存映射文件mmap加载权重,例如:
Weights = torch.load(“model.bin”,mmap=True);
3) 使用并行加载的方式,将权重按层或模块拆分为多个文件,可google教程
4) 减少多线程开销,设置以下环境变量
export OMP_NUM_THREADS=1
5) 预热加载,提前预加载模型权重到内存
2.5 推理卡顿:纯模型/服务化拉起卡住、停止
问题现象:如果free -h中的free内存小于权重大小 / 机器数,纯模型拉起会卡死,过一段时间后进程被杀。
根据经验,可以确保一下free_mem >= (权重大小 / 机器数) * 1.3 (该计算方式待验证,但需要确保内存足够)
解决方案:重启/释放缓存。
推荐使用释放缓存的方式,可以在容器内运行以下指令:
sync; echo 3 > /proc/sys/vm/drop_caches
注意,每次跑完模型,请检查一下机器的host侧内存占用。
2.6 推理卡顿:首Curl请求卡死
问题现象:在服务化成功启动后出现首次curl请求发送后,无返回的现象;或者服务化拉起卡死的现象。
可能原因:多节点的服务化config.json有区别,或是除了需要写本机信息外的环境变量不一样。
例如,A、B两个8卡节点的服务化配置文件中,A配置了interNodeTLSEnabled=true,B配置了interNodeTLSEnbal=false。
容器A的环境变量中未设置确定性计算相关环境变量,容器B的环境变量中却有确定性计算相关的环境变量。尽管执行推理请求的节点确定性计算相关的环境变量是关闭状态,仍可能影响推理卡住。
所以,请一定要一一核对好每个8卡容器内的环境变量是一样的,服务化的config.json也需是一样的。
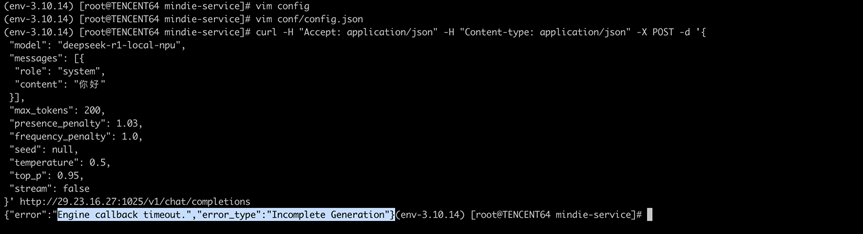
2.7 推理卡顿:大流量下curl请求超时
问题现象:服务启动后,在大流量下会出现挂死,具体表现为Curl请求超时,Aicore利用率为0:
所有卡利用率为0:
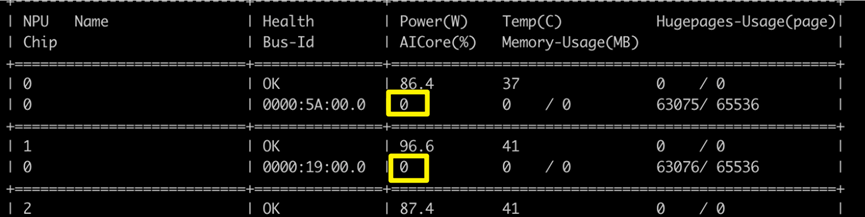
当前识别为重计算触发的问题,可通过修改MindIE Service的config文件进行临时规避。
要求maxseqen与maxprefilltoken参数配置为相同大小。
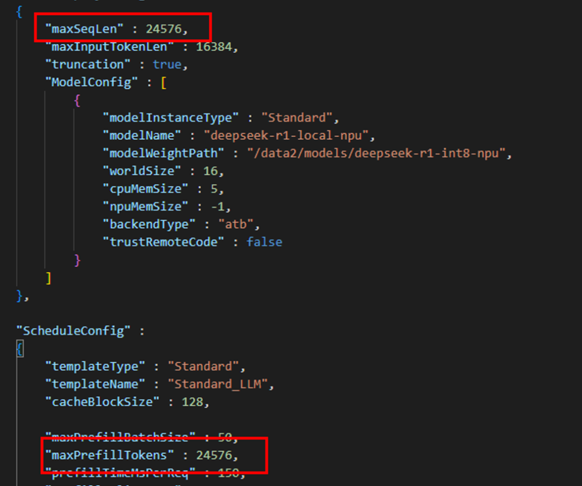
2.8 配置问题:服务化benchmark初始化失败
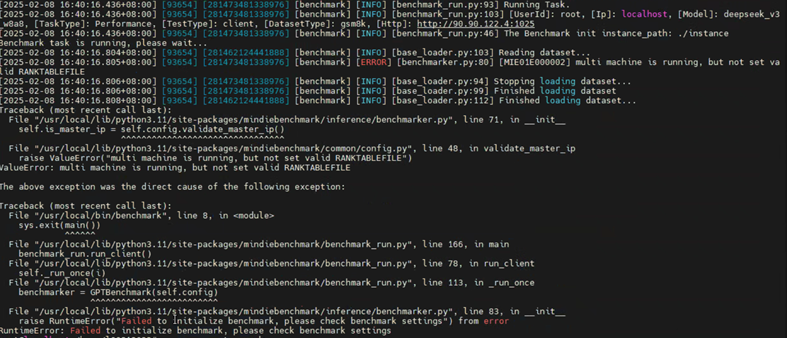
需正确配置Ranktable: export RANKTABLEFILE=/Path/To/ranktable[X].json
2.9 配置问题:Ranktable中的server id和container ip填写
ranktable中的server id和container ip均填写成主机IP,前提是起容器时需要设置成host模式:docker run --network host <image_name>,含义就是容器的ip地址=主机的ip地址,注意容器开放的端口不要和主机冲突。
2.10 日志采集:纯模型Profiling 采集
当前 MindIE atb-models 中已经内置了 Profiling 采集逻辑,核心代码在 atb-models/examples/run_pa.py 的 PARunner 中。我们可以通过以下环境变量对 Profiling 采集进行控制:
执行采集时,只需要配置环境变量,在modeltest下拉起性能测试,即可获取到 Profiling 数据。若需采集的卡数大于8,则需要在每个节点上同时开启以下环境变量:
开启环境变量后,参照性能测试,指令如下(可自行修改指令):
采集完成后,核心数据解析到$PROFILING_FILEPATH /ASCEND_PROFILER_OUTPUT 路径下。
2.11 日志采集:通用方法
遇到推理报错时,请打开日志环境变量,收集日志信息
2.12 Tokenizer 报错
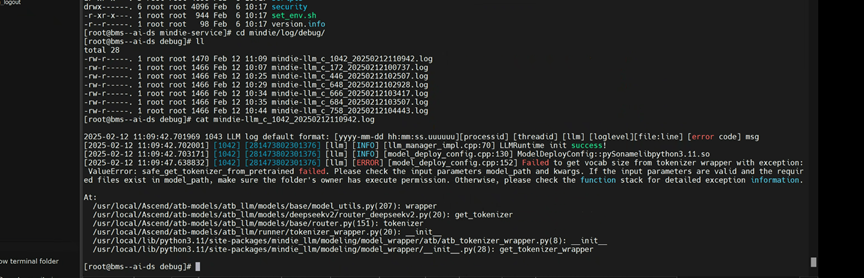
MindIE 报 XXX 错误,有一定误导性。实际上只要是 transformers 加载 tokenizer 报错,MindIE 会捕获所有错误,直接退出,并且不会显示真正错误原因。通常,transformers 加载 tokenizer 常见错误以及对应排查方法有:
词表文件损坏
检查 tokenizer.json 文件完整性,V3 和 R1 的词表不一样。
推荐使用 ModelScope 由 Unsloth 维护的 bf16 版本
transformers / tokenizer 版本不匹配
确认 transformers、tokenizer 版本:查看模型权重路径下的 config.json 中,transformers版本号。注意:不同的原权重由于fp8转bf16时的transformers版本不同,可能会有不同的transformers 配套,请以机器上的deepseek官方权重中的config.json中的transformers版本为准)
若怀疑Tokenizer的问题,可以使用以下Tokenizer 校验方法,创建一个 python 脚本,如果运行成功,则 tokenizer 加载无问题。若报错,请按照上述方法检查。
2.13 性能问题:推理性能不符合预期
首先,请确保使能AIV,关闭确定性计算。
其次,DeepSeek-R1 官方推荐服务化请求遵循以下配置,以达到预期性能:
将温度设置在0.5-0.7 范围内(推荐0.6),以防止出现无休止的重复或不连贯的输出。
避免添加 System Prompt;所有指令应包含在 User Prompt 中。
对于数学问题,建议在提示中加入以下指令:“请逐步推理,并将最终答案放在\boxed{}内。”
在评估模型性能时,建议进行多次测试并取平均结果。
若遇到精度问题,请确保使用openai接口。
此外,DeepSeek-R1系统模型在回答某些问题时倾向于绕过思考模式(即不输出“<think>\n\n</think>”),这可能会影响模型的表现。为了确保模型进行正确的推理,建议强制模型在每次输出的开头使用“<think>\n”。
2.14 权重路径和权限问题
问题描述:
在服务化拉起过程中出现权重路径不可用或者权重文件夹权限问题
解决方案:
注意保证权重路径是可用的,执行以下命令修改权限,注意是整个父级目录的权限:
2.15 16卡及以上配置推理测试类问题
2.15.1 服务化多节点推理超时停止
问题描述:
多节点参与的推理超过两小时不通信会超时,从而服务化报错。
解决方案:
当前版本可以写一个每小时调用健康监控接口的脚本,进行服务化保活。服务化监控探测接口参考MindIE官方文档:
健康探针接口-EndPoint管理面接口-MindIE1.0.0开发文档-昇腾社区
2.15.2 权重加载过程中/加载完成后卡死
遇到多节点推理拉起问题可以用一个轻量化的脚本尝试快速定位一下,卡死是否是由于节点间通信算子导致的(以AllReduce为例)。
首先需要在每个节点上(推理容器内)创建三个文件,分别是 hostfile, test_allreduce.sh, test_allreduce.py
如果该指令能成功跑通且有回显,则hccl出现问题的几率较小,可以定位范围缩小到模型加载的问题上(本方法为简易HCCL联通验证,HCCL连通完全校验请使用 hccl test 工具)。
如果该指令在计算过程中卡住,则hccl出现问题的几率较大,可以再容器外再次尝试该验证方法。若在容器外也无法验通,可以按照1.4.1章节对机器进行前置准备,再进行容器外、容器内的连通验证。
如果该指令直接拉起失败,检查脚本是否有写错的地方,如sh脚本中各个参数。
2.15.3 Unicode Error
问题描述:
出现UnicodeEncodeError: 'ascii' codec can't encode character \uff5c in position 301:ordinal not in range(128) 报错
解决方案:
这是因为由于系统在写入或打印日志ASCII编码deepseek的词表失败,导致报错,不影响服务化正常运行。如果需要规避,需要将/usr/local/Ascend/atb-models/atb_llm/runner/model_runner.py的第145行注释掉:
2.15.4 Not set valid RANKTABLEFILE报错
问题描述:
在执行服务化benchmark测试时,报错 not set valid RANKTABLEFILE。
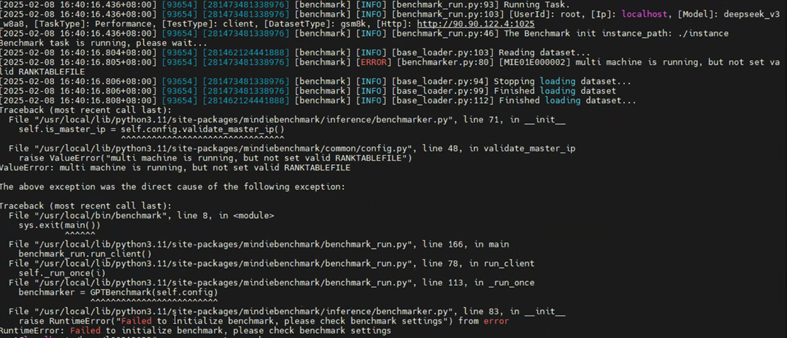
解决方案:
需在每台机器上正确配置RANKTABLEFILE文件路径的环境变量。
